




To understand this security issue, first, we need to understand what is cache, why it is used and how it is used. Okay, let's begin now.
What is an HTTP cache?
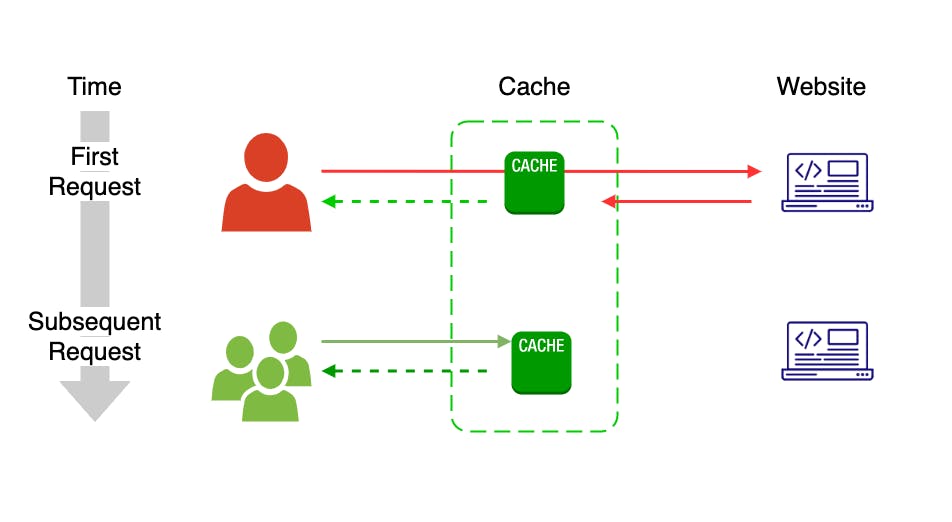
Sometimes HTTP cache is also called web cache. A Web cache is like a temporary storage place that sits between web servers and clients and watches incoming requests, saving copies of the responses like HTML pages, images, and files. Then, if it receives another request for the same URL, it uses the response that it already has, instead of asking the origin server.
Why it is used?
There are two main reasons that HTTP caches are used: To reduce latency - Because the request is satisfied from the cache (which is closer to the client) instead of the origin server, it takes less time. This makes the Web seem more responsive. To reduce network traffic - it reduces the amount of bandwidth used by a client and server. Also, reduces the load on the server.
How it is used?
All caches have a set of rules that they use to determine when to serve a representation from the cache if it's available. Some of these rules are set in the protocols (HTTP 1.0 and 1.1), and some are set by the administrator of the cache. If a server had to send a new response to every single HTTP request separately, this would likely overload the server, resulting in latency issues and a poor user experience, especially during busy periods. Caching is primarily a means of reducing such issues.
This greatly eases the load on the server by reducing the number of duplicate requests it has to handle.
HTTP Cache Poisoning
HTTP cache poisoning is an advanced technique whereby an attacker exploits the behavior of a web server and cache so that a harmful HTTP response is served to other users.
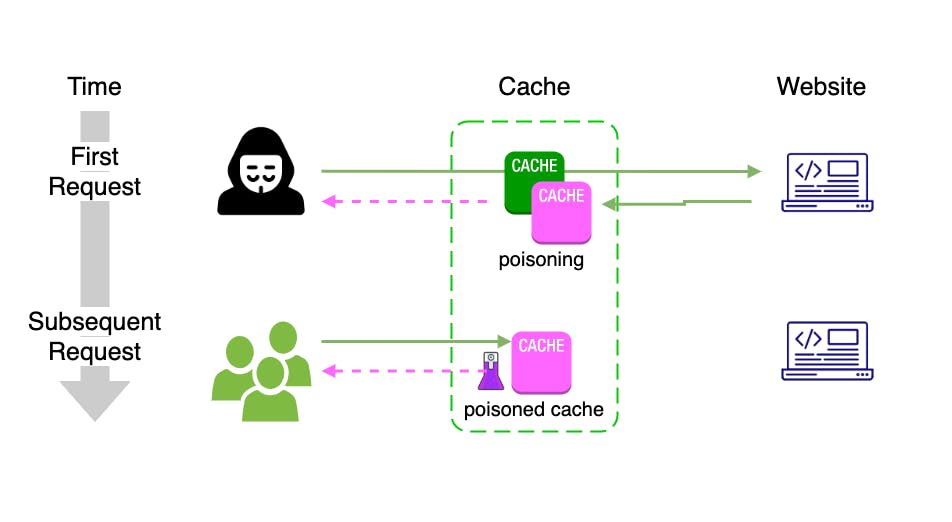
As the poisoned cache is more a means of distribution than a standalone attack, the impact of HTTP cache poisoning is inextricably linked to how harmful the injected payload is. As with most kinds of attacks, web cache poisoning can also be used in combination with other attacks to escalate the potential impact even further.
The poisoned response will only be served to users who visit the affected page while the cache is poisoned. As a result, the impact can range from non-existent to massive depending on whether the page is popular or not. If an attacker managed to poison a cached response on the home page of a major website, for example, the attack could affect thousands of users without any subsequent interaction from the attacker.
How HTTP cache is poisoned?
In order to understand how the HTTP caches are poisoned, we need to understand what is HTTP headers and how it works.
HTTP headers let the client and the server pass additional information with a request or response. When you visit a website, your browser sends a request to the webserver to obtain data or information from it, e.g. an HTML file (i.e. a web page). Both in the request and in the server's response, some meta-information is exchanged in addition to the actual data. This is summarized in the HTTP header.
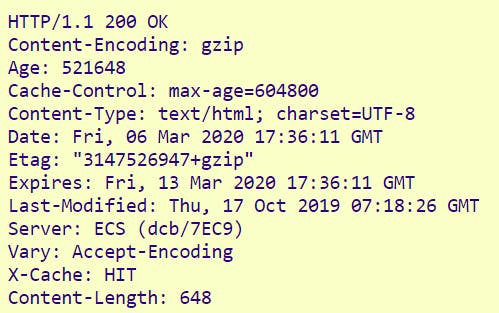
The individual lines are called "header fields". Each consists of a name/value pair separated by a colon. This header information is mainly used for coordination between the client (browser) and the server. It is ensured that the client can understand the form of the request and that meets the browser's expectations.
A web cache works by storing HTTP responses for a certain amount of time-based on a set of rules. The main way a web cache keeps track of what response content to cache, is through something called cache keys.
Cache keys are parts of an HTTP request that the cache will use to uniquely identify a response. Typically a cache key consists of the values of one or more response headers as well as the whole or part of the URL path.
It turns out that many applications allow inputs such as query strings, header values, and cookie values that aren't part of the cache key to be reflected in the response. Inputs that aren't part of the cache key are called unkeyed inputs.
HTTP cache poisoning attack relies on manipulation of unkeyed inputs, such as HTTP headers. Cache ignores unkeyed inputs when deciding whether to serve a cached response to the user. This behavior means that you can use them to inject your payload and elicit a "poisoned" response which, if cached, will be served to all users whose requests have the matching cache key.
Preventing from HTTP Cache Poisoning
You must review the caching configuration of your caching server to ensure that when calculating cache keys it is avoiding to make any cache key decisions using untrusted user inputs.
Find all inputs (headers, cookies, and query strings) that are reflected in the response without being part of the cache key. Make sure to either disable them, remove them in the cache layer or add them to the cache key.
If you are considering excluding something from the cache key, rewrite the request instead.
Don't accept fat GET requests. Be aware that some third-party technologies may permit this by default.
Patch client-side vulnerabilities even if they seem unexploitable.
Vulnerability analysis of your web application to make sure that it is not vulnerable to Cross-site Scripting attacks so that malicious responses will not be stored in the cache.
Conclusion: Thus, this is about HTTP cache poisoning and how to prevent it. We will try to explore deeper in upcoming blogs. Shoot your questions in the comment section.
Writer: Mounick
About me: A DevOps engineer and serverless evangelist with a love of all things AWS, innovation, security, software architecture, and technology
Follow me on LinkedIn